![[CS - 데이터베이스] Index에서 Column 사용 (또는 선정) 기준](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcuS9y4%2FbtrYV87tgPM%2FAAAAAAAAAAAAAAAAAAAAAICBnSlajxVTseTuvFOy_pieIts8Tt_PX_iBHru_Nn1n%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3Dk8F2yvLTHBORNItywM952J9nbcw%253D)
Index에서 Column을 선정하는 기준
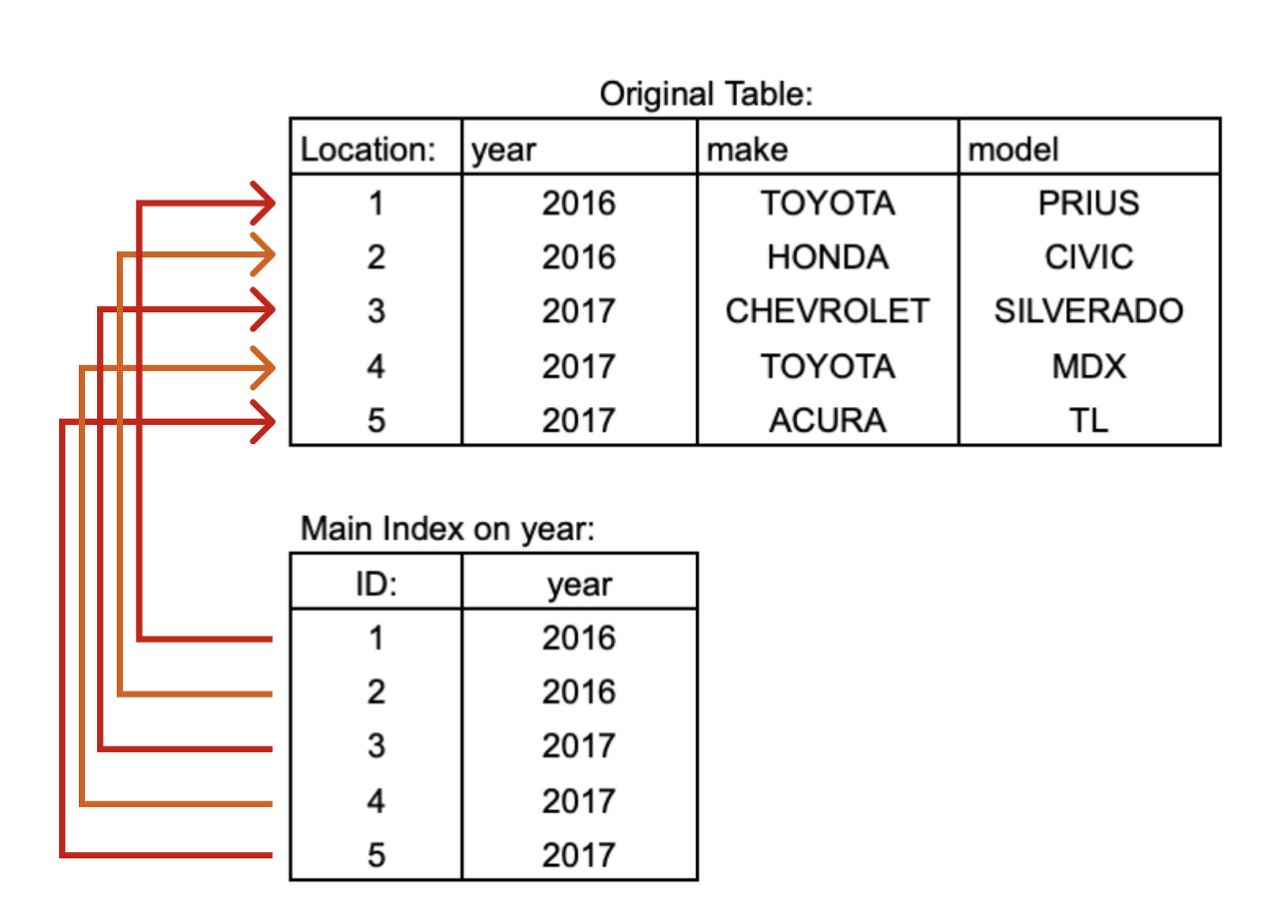
DB에서 어떤 Column을 선정하느냐에 따라 다양한 Index를 만들 수 있다. 우리는 어떤 Column을 선정하는 것이 좋을까?
이 부분은 굉장히 빈번하게 나오는 내용이지만 개념은 간단하다. 그래서 결과부터 알아보고 그 이유를 살펴보자.
Column 선정 기준
Index에서 사용하는 Column은
- 조회 빈도가 높아야 한다.
- 수정 빈도가 낮아야 한다.
- 카디널리티가 높아야 한다.
- 선택도가 낮아야 한다.
왜냐하면,
- Index가 SELECT ~ WHERE ~ 절이기 때문에 자주 쓰이는 것이어야 한다.
- 수정될 때마다 데이터가 재정렬되기 때문에 그 비용이 크면 안되기 때문이다.
- 카디널리티는 ‘얼마나 중복이 안되냐’, ‘얼마나 고유한 값이냐’를 말한다. 최대한 중복을 피해야 한다는 뜻이다.
- 선택도는 카디널리티의 반대말이다. 중복이 덜 되어야 Index 효과가 크기 때문이다.
쉽게 말해서 많이 조회되고, 수정이 덜 되고, 최대한 겹치는 값이 없는 Column이어야 한다.
Index의 특성
Column 선정 기준을 공부할 때, Index의 특성과 함께 떠올린다면 전체 내용을 보다 유기적으로 기억할 수 있다.
Index라는 건, 무수히 많은 데이터베이스에서 찾고자 하는 값을 효과적으로 찾도록 도와주는 장치이다.
이 장치를 만드는 것은 시간도 들고 공간도 필요하다. 또한, 데이터베이스가 수정되면 Index 또한 수정되어야 한다.
보통은 하나의 테이블에 4~5개의 Index를 만드는 편이다.
데이터의 중복이 많은 경우는 (예를 들면 남/녀, true/false 등. 각 비율은 중요치 않음) Index를 생성하기에 부적합하다.
데이터의 양이 많을수록 Index의 효과를 톡톡히 볼 수 있고, Join 조건으로 자주 사용되는 Column 또한 Index를 만들기 적합하다.
하나의 DB 테이블에서 어떤 Column을 사용하느냐에 따라 여러 Index를 만들 수 있다.
Index 하나를 만드는 것 또한 비용이 들기 때문에 좋은 Column을 골라 효율적인 Index를 만드는 것이 중요하다.
그래서 Column 선정 기준을 배우는 것이다.
'CS > 데이터베이스' 카테고리의 다른 글
| [CS - 데이터베이스] 데이터베이스의 정규화 (0) | 2023.02.13 |
|---|---|
| [CS - 데이터베이스] Index를 Hash Table이 아닌, B+Table로 구현하는 이유 (0) | 2023.02.13 |
| [CS - 데이터베이스] DB의 Index (0) | 2023.02.13 |
| [CS - 데이터베이스] Transaction과 Deadlock (0) | 2023.01.28 |
| [CS - 데이터베이스] RDB와 NoSQL (2) | 2023.01.26 |