![[CS - 데이터베이스] Index를 Hash Table이 아닌, B+Table로 구현하는 이유](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FdZ7fjQ%2FbtrYYqmu9qy%2FAAAAAAAAAAAAAAAAAAAAANFOs8rXqFXksQ7bbeYareb8Ut7PJ9J5oXR_ZHCb2d3K%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3DTApBFqcUpz7eFoPZTE0Bw85p%252FSU%253D)
Index를 Hash Table이 아닌, B+Table로 구현하는 이유
“Hash Table은 검색의 시간복잡도가 O(1)로, O(logn)인 B+Table보다 빠르다.
그럼에도 불구하고 왜 Index를 B+Table로 구현하는가?”
이 질문에 답하기 위해선, 우선 B+Table이 어떻게 구현되어 있는지 알아야 한다. 이 개념부터 살펴보자.
B+Table 이란?
두 가지의 키워드로 요약할 수 있다. 정렬과 부등호.
B+Table은 데이터를 정렬하여 저장하기 때문에 부등호 연산, 즉 범위 검색에 유용하다.
왜냐하면, B+Table의 각 노드에는 값과 범위가 저장되기 때문에, root 노드에서 시작해서 찾고자 하는 값의 범위에 맞는 노드를 탐색해나가는 원리이기 때문이다.
*B+Table의 B는 Balanced를 의미한다.

우측에는 데이터베이스, 좌측에는 이름 column을 search-key로 한 index가 있다. index가 B+Tree로 저장되는 형태를 살펴보자.

이렇게 부모 노드에는 이름과 범위가, 자식 노드에는 부모 노드의 범위에 속한 이름과 또 하나의 작은 범위가 저장된다.
여기서 ‘배준석’을 찾는 연산을 살펴보자.

첫번째로, 배준석은 박현지보다 큰 값이기 때문에, 박현지보다 우측 자식 노드를 탐색한다.
두번째로, 배준석은 정재헌보다 작은 값이기 때문에, 정재헌보다 좌측 자식 노를 탐색한다.
세번째로, 배준석의 값을 찾는다.
위는 B+Table에서 등호 연산이 실행되는 과정이다. 이번에는 B+Table의 장점인 부등호 연산이 이루어지는 과정을 살펴보자.
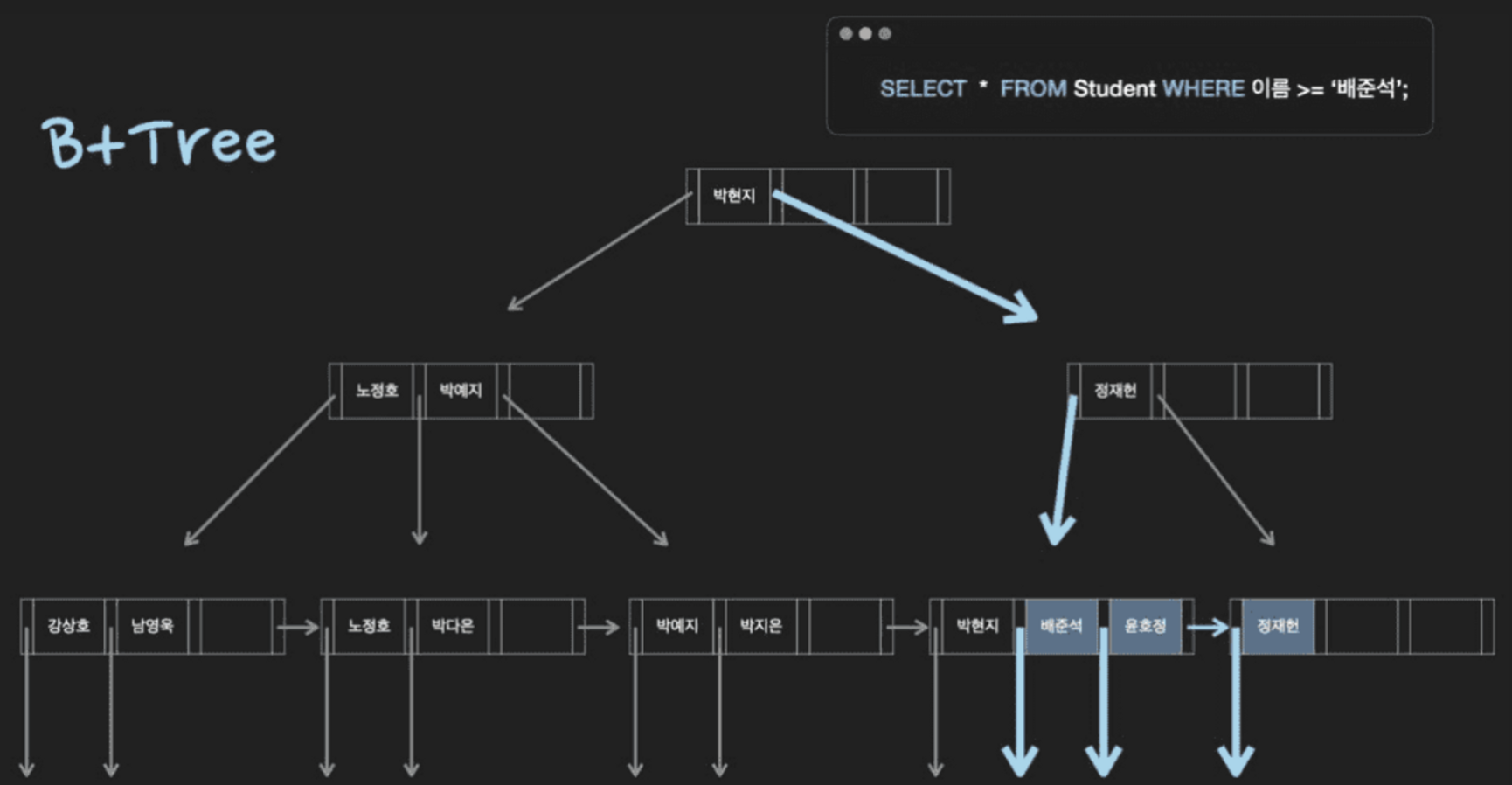
우리가 찾고자 하는 값은 ‘배준석’보다 큰 값들이다.
B+Table이 부등호 연산에 강점을 보이게 하는 이유는 Leaf 노드에서 이동할 수 있다는 점이다.
배준석이 위치한 값을 찾고, 이 Leaf 노드에서 큰 값들을 탐색해나간다. (베준석 → 윤호정 → 정재헌)
그래서 Index를 Hash가 아닌 B+Table로 구현하는 이유는?
Index는 검색 시간복잡도가 O(1)인 대신, 등호 연산에 유리하다.
B+Table은 검색 시간복잡도가 O(logn)인 대신, 부등호 연산에 유리하다.
등호 연산만 존재하는 경우 Hash가 더 유리할 수 있으나, Index의 검색은 대부분 부등호 연산이기 때문에, B+Table로 구현한다.
'CS > 데이터베이스' 카테고리의 다른 글
| [CS - 데이터베이스] 데이터베이스의 정규화 (0) | 2023.02.13 |
|---|---|
| [CS - 데이터베이스] Index에서 Column 사용 (또는 선정) 기준 (0) | 2023.02.13 |
| [CS - 데이터베이스] DB의 Index (0) | 2023.02.13 |
| [CS - 데이터베이스] Transaction과 Deadlock (0) | 2023.01.28 |
| [CS - 데이터베이스] RDB와 NoSQL (2) | 2023.01.26 |