![[CS - 데이터베이스] 데이터베이스의 정규화](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FzLiiT%2FbtrY5kGIdJY%2Fs2JJfy5Kkp0hqjctMOOfj1%2Fimg.png)
데이터베이스의 정규화
정규화(Normalization)란?
데이터베이스의 중복을 피하기 위해 데이터를 분해하고 구조화하는 작업.
중복이 많이 발생하면 이상 현상이 발생하기 때문에 정규화 작업을 해주어야 함!
정규화란 RDBMS에서 중복을 최소화하기 위해 데이터를 분해하는 작업을 말한다.
중복된 데이터를 만들지 않으면, 무결성을 유지하면서 이상 현상을 방지할 수 있고, DB 저장 용량 또한 효율적으로 관리할 수 있다.
또한, 테이블 구성을 논리적이고 직관적으로 할 수 있고, 데이터베이스 구조를 확장에 용이해진다.
*이상 현상이란?
데이터의 중복이 많아서 데이터 처리가 잘 안 되는 경우를 말한다.
- 삽입 이상 : 원하지 않는 데이터 삽입되는 상황 || 데이터 삽입 시 관련 없는 데이터 추가 삽입해야하는 상황
- 갱신 이상 : 데이터 수정 시 일관성이 위배되는 상황
- 삭제 이상 : 데이터 삭제 시 엉뚱한 데이터 삭제되는 상황
정규화의 종류 및 단계
이 부분 개념을 글로만 보면 무슨 말인지 이해하기 어려우니, 예를 들어보자.
각 정규형의 정의와 더불어 한 헬스장의 수강생 등록 현황 테이블을 만드는 상황을 함께 살펴보자 (코딩애플 짱)
제 1 정규화 (1NF)
테이블 컬럼이 원자값(하나의 값)을 갖도록 테이블을 분리시키는 것을 말한다.
어떤 릴레이션에 속한 모든 도메인이 원자값만으로 되어 있어야 하고, 모든 속성에 반복되는 그룹이 나타나지 않아야 하며, 기본키를 사용하여 관련 데이터의 각 집합을 고유하게 식별할 수 있어야 한다.
뭔 개소리냐?
쉽게 말해서, 한 칸에 하나의 데이터만 넣는다는 말이다.
상황과 함께 살펴보자.

여기, 운동 열쩡이 빼어난 김민수씨가 있다. (김민수의 수가 빼어날 수 자를 쓰나 보다)
김민수씨는 골프를 추가로 등록했다. 우리는 이 데이터베이스 테이블에 어떻게 등록해야할까?

이렇게 하면 될까?
만약 이런 테이블에서 골프 초급을 등록한 회원들의 이름을 추출하려면 어떻게 해야 할까?
프로그램 중에 골프 초급을 포함하는 회원의 이름을 어쩌고 저쩌고 …
비효율적인 일이다.
그래서 우리는 하나의 줄에 하나의 정보만 담기로 했다. 여러 개를 같이 담으니까 나중에 정보를 다룰 때 귀찮은 일이 많아지기 때문이다.

이렇게 밑에 한 줄을 추가로 작성해주면서, 한 칸에 하나의 데이터만 담을 수 있게 되었다.
이게 바로, 원자값을 갖도록 한다는 제 1 정규형을 만족하는 데이터베이스이다.
제 2 정규화 (2NF)
테이블의 모든 칼럼이 완전 함수적 종속을 만족해야 한다.
완전 함수적 종속이란 ’X → Y’ 라고 가정했을 때, X 의 어떠한 애트리뷰트라도 제거하면 더 이상 함수적 종속성이 성립하지 않는 경우를 말한다. 즉, 키가 아닌 열들이 각각 후보키에 대해 결정되는 릴레이션 형태를 말한다.
진짜 뭔 개소리냐?
약간 쉽게 말해서, 테이블의 복합 키에 대한 partial dependency를 제거한 테이블이다.
진~짜 쉽게 말해서, 하나의 테이블에는 하나의 주제에 관한 데이터만 넣는다는 얘기다. (현재 주제와 관련 없는 컬럼은 다 제거)
상황으로 다시 보자.

우리는 추가로 가격, 납부 여부에 관한 정보로 넣으려고 한다.
우리는 이렇게 데이터를 추가해도 될까?
당연히 되지. 근데 이게 과연 최선일까?
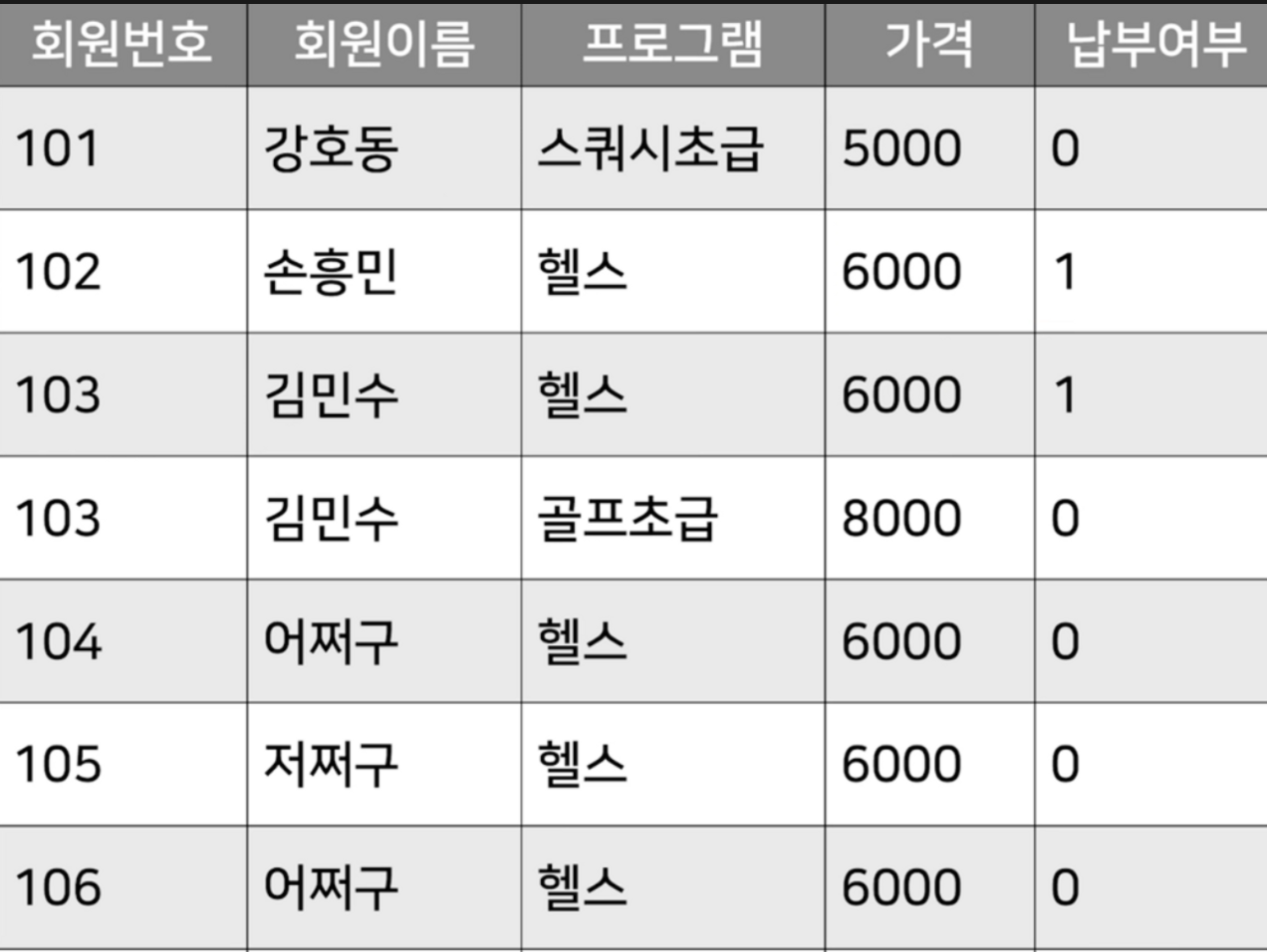
만약 수강생이 만 명이 되는 상황에서 헬스장의 가격을 8000원으로 수정하려고 한다.
이런 테이블에서는 우리는 만 번이나 값을 수정해야 한다. 상당히 비효율적이다.
어떻게 하면 효율적일까?

잘 보면, 사실 수강생 등록 현황 테이블과 가격 테이블은 상관이 없는 테이블이다. 그렇기 때문에 가격 정보는 따로 분리한 뒤, 우리는 우측의 가격 테이블에서 한 개의 값만 수정하면 된다.
즉, 다른 주제의 데이터라는 얘기다. 그래서 이렇게 다른 주제는 따로 분리하는 것이 더 효율적이다.
그리고 이것은 제 2정규형을 만족하는 테이블이다.

조금만 더 정확하게 표현해보자.
이 테이블에서 ‘회원 번호’와 ‘프로그램’을 합치면 각 칸을 고유하게 식별할 수 있다. 이때 ‘회원 번호’와 ‘프로그램’은 복합키가 된다.
근데 ‘가격’ 컬럼은 복합 키 중 하나인 ‘프로그램’의 따까리다. 프로그램에 의해 가격이 결정되기 떄문이다. (프로그램’의’ 가격을 명시한 컬럼이기 때문. 어렵게 생각 ㄴㄴ)
이때 ‘가격’ 컬럼과 ‘프로그램’ 컬럼을 같은 테이블에 두면 partial dependency가 발생한다고 말한다.
우리는 제 2 정규화를 위해 ‘가격’ 컬럼을 분리해야 한다.
즉, 복합키에 종속되는 컬럼을 다른 테이블로 분리해야 한다. 종속성을 없애야 하는 것이다.
그리고 이를 제 2 정규화라고 한다.
제 3 정규화 (3NF)
어떠한 키도 기본 키에 대해서 이행적으로 종속되지 않으면 제 3 정규형을 만족한다고 본다.
이행적 종속 : A → B, B → C면 A → C가 성립된다
릴레이션이 2NF에 만족하고, 기본키가 아닌 속성들은 기본키에 의존한다.
끝까지 뭔 개소리냐?
상황과 함께 같이 살펴보자.

여기, 한 헬스장의 수업에 관한 데이터 테이블이 있다.
근데 만약 이상구씨가 학벌 세탁을 한 사실이 들통나서, 고려대가 아니라 하버드 대학교였다면?
이상구씨가 적혀있는 모든 칸을 하나씩 다 수정해야 하는 비효율적인 일이 발생한다.
우리는 여기서 어떻게 더 개선시킬 수 있을까?

일단 이 테이블은 제 2 정규형을 만족하는 테이블이다. 복합키도, partial dependecy도 없기 때문이다.
여기서 '출신대학' 컬럼을 유심히 쳐다보자.

출신대학 컬럼은 기본키가 아닌, 일반 ‘강사’ 컬럼에 종속된 컬럼이다.
우리가 앞에서 배운 제 2 정규화는 복합키의 partial dependency를 없애기 위해 종속된 컬럼을 제거한 것이다.
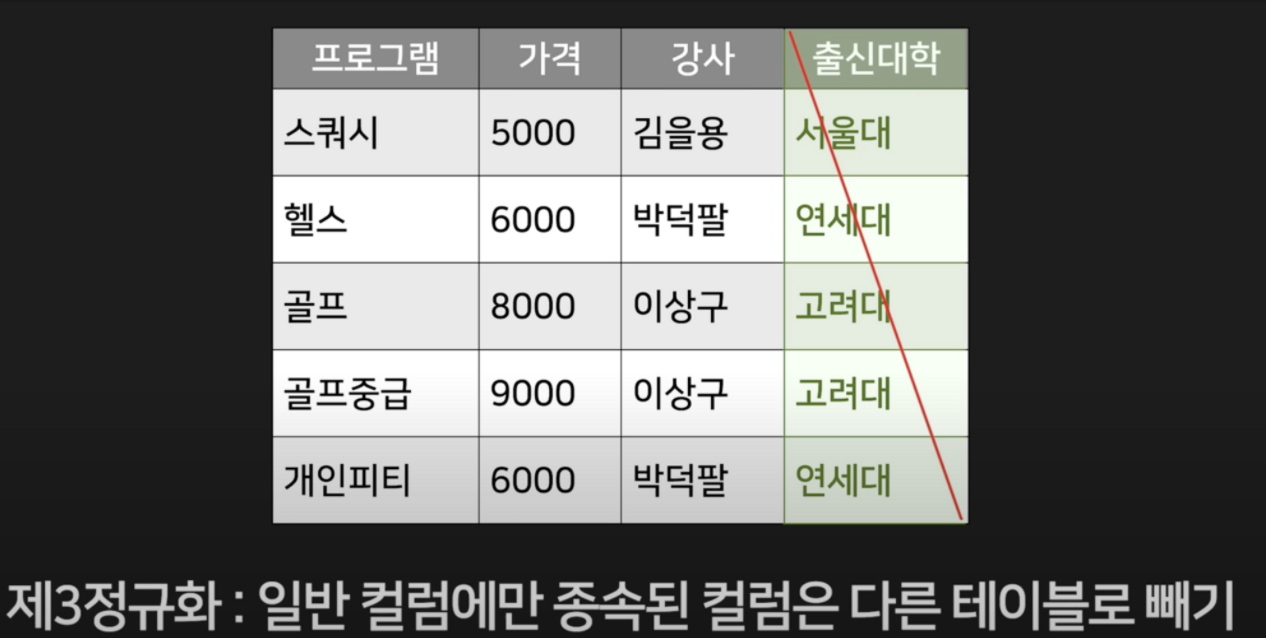
제 3 정규화는 이거랑 비슷하다.
제 3 정규화는 기본키와 관련이 없을 지라도, 일반 컬럼에라도 종속된 컬럼을 제거하는 것이다.

이렇게 제거할 수 있다.
이 테이블은 제 3 정규형을 만족하는 테이블이다.
출처
https://www.youtube.com/watch?v=Y1FbowQRcmI
https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Database/%EC%A0%95%EA%B7%9C%ED%99%94(Normalization).md
'CS > 데이터베이스' 카테고리의 다른 글
| [CS - 데이터베이스] Index를 Hash Table이 아닌, B+Table로 구현하는 이유 (0) | 2023.02.13 |
|---|---|
| [CS - 데이터베이스] Index에서 Column 사용 (또는 선정) 기준 (0) | 2023.02.13 |
| [CS - 데이터베이스] DB의 Index (0) | 2023.02.13 |
| [CS - 데이터베이스] Transaction과 Deadlock (0) | 2023.01.28 |
| [CS - 데이터베이스] RDB와 NoSQL (2) | 2023.01.26 |